An Encoding for Robust Immutable Storage
11. June 2020 (v0.1)
We present an Encoding for Robust Immutable Storage (ERIS) that can be used with a content-addressable storage to encode arbitrary content into a set of uniformly sized encrypted blocks such that the content can only be reassembled to the original content given a read capability.
Additionally, a verification capability can be derived from the read capability that can be used to enumerate blocks required to reassemble the content and verify the integrity of blocks without being able to read the content. This allows peers to cache the content whit plausible deniability of being able to read the content.
We illustrate how ERIS can be used to build as a building block for robust, decentralized applications and demonstrate how ERIS can leverage existing peer-to-peer technology (such as IPFS).
Table of Contents
1 Introduction
The one so like the other
As could not be distinguish’d but by names.
— William Shakespeare, Comedy of Errors
Unavailability of content on computer networks is a major cause for reduced reliability of networked services [Polleres_Kamdar_Fernández_Tudorache_Musen_2020].
Availability can be increased by caching content on multiple peers. However most content on the Internet is identified by its location. Caching location-addressed content is complicated as the content receives a new location.
An alternative to identifying content by its location is to identify content by its content itself. This is called content-addressing. The hash of some content is computed and used as an unique identifier for the content.
Content-addressed content is much easier to cache as the content is completely decoupled from any physical location. It is much easier to ensure availability of content-addressed content than it is for location-addressed content. Systems like IPFS use content-addressing for exactly this reason.
Authenticity of content is automatically ensured with content-addressing (when using a cryptographic hash) as the identifier of the content can be computed and be checked to match the requested identifier.
However, naive content-addressing has certain drawbacks:
- Large content is stored as a large blob. In order to optimize storage and network operations it is better to split up content into smaller uniformly sized blocks and reassemble blocks when needed.
- Confidentiality: Content is readable by all peers involved in transporting, caching and storing content.
We propose ERIS, a scheme that addresses the issues with naive content-addressing that we hope may provide a robust foundation for storing immutable content.
1.1 Requirements
The requirements for the ERIS are:
- Availability of content: Content can be replicated and cached.
- Authenticity: Authenticity of content can be verified.
- Plausible deniability for peers: Peers that transport, store and cache data blocks can do this without being able to read the content.
- URN reference: Content can be reference with a single URN.
- Simplicity: The encoding should be as simple as possible in order to allow correct implementation on various platforms and in various languages.
1.2 Scope
A concept is tolerated inside the microkernel only if moving it outside the kernel, i.e. permitting competing implementations, would prevent the implementation of the system’s required functionality.
— Jochen Liedtke, On μ-Kernel Construction [liedtke1995micro]
ERIS describes how arbitrary content (sequence of bytes) can be encoded into a set of uniformly sized blocks and an identifier with which the content can be decoded from the set of blocks.
ERIS does not prescribe how the blocks should be stored or transported over network. The only requirement is that a block can be referenced and accessed (if available) by the hash value of the contents of the block. In section Storage and Transport we show how existing technology (including IPFS) can be used to store and transport blocks.
There is also no support for grouping content or mutating content. In section Namespaces we describe how such functionality can be implemented on top of ERIS.
The lack of certain functionalities is intentional. ERIS is an attempt to find a minimal common basis on which higher functionality can be built. Lacking functionality in ERIS is an acknowledgment that there are many ways of implementing such functionality at a different layer that may be optimized for certain use-cases. In section Applications we illustrate how such functionality may be implemented using ERIS.
2 ERIS encoding
The scheme we propose defines an encoding of content into uniformly sized content-addressed, encrypted data blocks and a reference (an URN) that can used to reassemble the blocks to the original content. We call the reference that can be used to reassemble the blocks the read capability.
Given the read capability and the encrypted data blocks the original content can be decoded.
From the read capability a verification capability can be deterministically derived. The verification capability allows holder to enumerate all blocks required to reassemble the content and verify the integrity of the blocks. The verification capability can not be used to decode the unencrypted content. The verification capability allows plausible deniable caching of content.
An optional convergence secret can be specified when encoding the content. This provides (optional) protection from certain attacks (see Convergence secret).
Figure 1: Overview of ERIS
2.1 Preliminaries
2.1.1 Cryptographic primitives
Following cryptographic primitives are used by ERIS:
- Cryptographic hash function
- BLAKE2b [aumasson2013blake2,saarinen2015blake2] with output size of 256 bit (32 byte)
- Symmetric Key Cypher
- ChaCha20 IETF variant [nir2015chacha20]
- Padding algorithm
- According to ISO/IEC 7816-4
- Key derivation
- Using keyed and salted BLAKE2b. Derived key is
BLAKE2b(key=key, message={}, salt=subkey_id, personal=ctx).
The cryptographic primitives are readily available in libraries for many platforms and programming languages (e.g. libsodium).
2.1.2 Content-addressable storage
For storage of blocks we rely on a content-addressable storage which provides two functions:
cas-put!(block)- Stores a 4kB
blockof data and returns a reference such thatref = BLAKE2b(block). cas-get(ref)- Given a reference returns a block of data that was previously stored, such that
ref = BLAKE2b(block). If there is no block stored for the reference then throw an error.
A content-addressable storage can be implemented with a hash-map (in-memory), a key-value store (e.g. LevelDB), a relational database or using systems like IPFS (see Storage and Transport).
2.2 Read and verification key
ERIS uses two keys to encrypt content:
- read key
- The key used to encrypt the content. The read key is
BLAKE2b(content). If a convergence secret is given the read key isBLAKE2b(content, key=covergence-secret)(using keyed hashing). - verification key
- Derived from the read key using the subkey id
1and personalization context set to the UTF-8 encoding of the string"eris.key".
2.2.1 Convergence Secret
Using the hash of the content as key is called convergent encryption.
Because the hash of the content is deterministically computed from the content, the key will be the same when the same content is encoded twice. This results in deduplication.
However convergent encryption suffers from two known attacks: The Confirmation Of A File Attack and The Learn-The-Remaining-Information Attack [Zooko2008].
A defense against both attacks is to use a convergence secret. This results in different keys and different URNs when encoding the same content with different convergence secret.
In section Namespaces we describe how convergence secrets can be used.
2.3 Encoding
The encoding process takes the content (as sequence of bytes), the read key and the verification key and returns a root reference (32 bytes) and a level count (positive integer with maximum value 12) which denotes the height of the Merkle tree.
The encoding process is:
- Content is first padded (see Cryptographic Primitives) to a multiple of 4kB.
- Content is then encoded with the symmetric key cypher using the
read keyand nonce set to0. If content is larger than 256 GB use nonce0for first 256 GB and increment nonce for successive chunks of 256 GB. - Encrypted content is split into blocks of size 4kB. The blocks holding encrypted content are called data blocks.
- Store data blocks in content-addressable storage and get data block references.
- Combine the data block references in a Merkle tree and return the reference to the root node (root reference) and the height of the Merkle tree (level).
The construction of the Merkle tree is described in the following section.
2.3.1 Merkle tree
After encrypting the content and placing the data blocks in the content-addressable storage we may have a large number of data block references. To retrieve the content we need all these references, which is impractical. Merkle trees allow us to hold a single reference that will allow us to discover all data block references.
The idea is to store references to data blocks in nodes of a tree. The nodes are themselves stored in the content-addressable storage and can be referenced and accessed in the same way data blocks can be referenced and accessed.
For illustration purposes we will show Merkle tree with arity two (two child references) the ERIS scheme uses arity 128.
If the content fits in one single data block (content smaller than 4kB) then return the data block reference and level 0.
If there are multiple data blocks combine them in a Merkle tree of arity 128. If there are less than 128 child nodes to be collected in a node the node is filled with null references (32 bytes of zeroes). The size of a node is always exactly 4kB (128 32 byte references).
Nodes of the Merkle tree are encrypted using the verification key and a nonce derived from the position of the node in the tree.
Encrypted nodes are stored in the content-addressable storage and references are placed in a node in the next higher level.
Note that encrypted nodes are indistinguishable from encrypted data blocks. We will refer to encrypted nodes and encrypted data blocks as blocks.
The Merkle tree is constructed until there is a single node on a level. This is the root reference. Note that the root reference is always the first of its level.
Figure 2: Merkle tree
2.3.2 Nonce from position
We identify the position of a node in the Merkle tree with the level and the count of nodes in the level (e.g. node-1-2 is the third node from left on level one).
We can encode the path from the root to a node by describing which child reference we have to follow. For example to reach node-1-1 from the root node (node-3-0) the path is: left, right. If we use 0 for left and 1 for right: (0,1).
All nodes at level 1 have a path of length two from the root: (0,0) for node-0-0 or (1,0) for node-1-3.
Notice that the path to a leaf node is the base-2 encoding of the count in the level: node-1-3 has count 3 which in binary (base-2) is (1,1) - the path to reach node-1-3 from the root.
For internal nodes (not at level 0) the same thing. To reach node node-2-1 we take the path (1) which is the base-2 encoding of it’s count in the level.
However we have the problem of distinguishing (1) (node-2-1) from (0,1) (node-1-1). We solve this by introducing an additional variable X that denotes a path not taken yet. We can now encode all nodes to a fixed size:
node-1-1:(0,1)node-1-3:(1,1)node-2-1:(1,X)node-2-0:(0,X)node-3-0:(X,X)
This “path” can be encoded into a nonce that we can use for encrypting the nodes.
In ERIS there are at most 128 child references per node, the path to a node can be computed by base-128 encoding the count of a node in a level. We use the value 255 as X and a maximum path length of 12. This sequence of 12 integers can be directly mapped to a 12 byte nonce.
For example in ERIS (with Merkle tree of arity 128):
node-1-1:(0,0,0,0,0,0,0,0,0,0,0,1)node-5-3:(0,0,0,0,0,0,0,3,255,255,255,255)node-4-3042:(0,0,0,0,0,0,0,23,98,255,255,255)node-8-294:(0,0,0,2,38,255,255,255,255,255,255,255)
The nonce directly identifies the position and is thus not reused.
Note that the encoding is not efficient (values between 127 and 255 are not used) and limits the size of the Merkle tree and thus the size of the content that can be encoded with ERIS (see Limits on size of content).
2.3.3 Second preimage attack
By encrypting the node using a nonce computed from the position of the node, we implicitly encode the position of the node into the hash reference of a node.
This prevents a node to be reused at an unforeseen position, preventing a second preimage attack.
2.3.4 Two-pass encoding
We have illustrated an algorithm that encrypts the entire content (or 256 GB chunks) in one go. This is not always possible (content may be larger than memory).
ERIS can also be implemented as a two-pass streaming algorithm.
In the first pass the read key is computed (using BLAKE2b).
In the second pass 4 kB blocks of data are encrypted (setting the initial block counter appropriately), stored in the content-addressable storage and added to the Merkle tree.
Unfortunately ERIS requires two passes over the content (as opposed to one single pass). This is a major drawback ERIS has.
Two-pass encoding is implemented in the Guile implementation.
2.4 URN
To read and/or verify content following information is required:
- The root reference (as returned by the encode process)
- The level of the Merkle tree (as returned by the encode process)
- The read or verify key
All this information can be packed in an URN, allowing ERIS encoded content to be referenced with a single identifier. We call such an identifier a capability as it gives holder capability to read or verify the content.
The root reference, level and key are encoded (with some additional information) to a binary capability as follows:
| Byte offset | Content | Length (in bytes) |
|---|---|---|
| 0 | version (0x00) |
1 |
| 1 | capability type (0x00 for read, 0x01 for verify) |
1 |
| 2 | level of root reference | 1 |
| 3 | root reference | 32 |
| 35 | read or verify key | 32 |
The capability URN is:
urn:eris:X
Where X is the Base32 encoding of the binary capability encoding.
For example the read capability for the string “Hail ERIS!” is:
urn:erisx:AAAAABM5XFVEHHR45X3YKU4ARK6MBHOZ4W22OTG5ME4NGO32H5P4SP3MCL3TK373WD53WSE6BOJACMNLBMKKFDKI25TAPP3SRY54QZ5WDX6Q
Note that we are currently using urn:erisx instead of urn:eris to denote experimental nature of the encoding. Once encoding is stabilized we will use urn:eris.
2.4.1 URN for blocks
Individual blocks can also be addressed with an URN.
There are many ways of doing this including:
- RFC 6920: Naming Things with Hashes
- Multihash: As used in IPFS
- Hashlinks: Work by the W3C Credentials Community Group
- hash-uri: Another specification draft.
ERIS does not specify a particular way of addressing blocks.
Note however that the we can not reuse the specifications above as the ERIS URNs do not only hold the hash value of the content but other information necessary for decoding the content.
2.5 Decoding
Given a read capability the content can be decoded by following child references of the nodes in the Merkle tree starting at the root.
Note that the level (encoded in capability) is essential for decoding the content as the nonce for decrypting nodes is computed from the level and count of node in level.
Integrity of content can be checked while decoding by re-computing the hash value of block and comparing them to the references.
2.6 Verifying
The verification capability allows everything the read capability allows except decrypting of the data blocks and thus reading of the content.
In particular a list of data blocks (and Merkle tree nodes) can be enumerated. This allows peers holding the verification capability to cache the content without being able to read it (plausible deniability for caching peers).
The integrity of all blocks required to decrypt the content can be verified with the verification capability.
2.7 Limits on size of content
640K ought to be enough for anybody.
— Misattributed to Bill Gates
The size of content that ERIS is able to encode is limited by the maximum depth of the Merkle tree.
The maximum depth of the Merkle tree is 13 levels (including data block level). This is because for every internal node maps to a unique nonce of 12 bytes (see Nonce from position).
The maximum size of content that ERIS can encode is thus \(128^{13} \cdot 4 \mathrm{kB}\), more than \(10^{20} \mathrm{GB}\).
2.8 On block size
The block size of 4kB was chosen for following reasons:
- Small content: Content smaller than 4kB still requires at least 4kB of storage as data block is padded to 4kB. A larger block size would make this worse.
- Reasonable overhead when encoding large files: The number of nodes required to combine data blocks into a single root reference is proportional to the number of references a node can hold. As nodes should be indistinguishable from data blocks they need to be the same size. Choosing 4kB (128 32 byte references) results in an overhead of less than 1% of the content size (see Size of Merkle tree).
Using multiple block sizes has also been considered. We believe that the additional complexity (in deterministically choosing the right block size) is not worth the storage efficiency.
2.9 Implementations and Demo
Implementations of ERIS are available for following programming languages:
- Guile: The initial implementation
- Javascript
We have also implemented a JavaScript web application to demonstrate ERIS: Encoding for Robust Immutable Storage (ERIS).
3 Applications
3.1 Storage and transport layers
ERIS is agnostic of storage and transport layers for blocks and only requires the ability to store uniformly stored blocks and access blocks by their hash code (see Content-addressable storage).
Storage layers can be implemented with:
- An in-memory hash-map.
- A key-value store (the Guile implementation uses LevelDB)
- A relational database
- IPFS
Blocks may be transported over network via:
- HTTP(S): A HTTP endpoint can be used to dereference blocks.
- Sneakernet: Blocks can be stored on a physical medium and transferred.
- Peer-to-Peer networks
3.1.1 IPFS
IPFS is an existing peer-to-peer network for sharing data.
By default IPFS does not provide any security mechanism, in the sense that content published on the network is world-readable. Content is split up into blocks and tied together using a Merkle tree (called UnixFS).
IPFS implementations also provide an interface to directly store and access blocks by their hash value - a content-addressable storage.
ERIS can use the IPFS block API as a content-addressable storage and have blocks transported from peer to peer via IPFS transport mechanisms. In that sense ERIS can be used as a secure alternative to the IPFS default UnixFS encoding of content.
This has been implemented and tested in the Guile and JavaScript implementations of ERIS.
3.2 Metadata
ERIS does not encode any metadata about the content. Metadata that references the content can be separately encoded and stored.
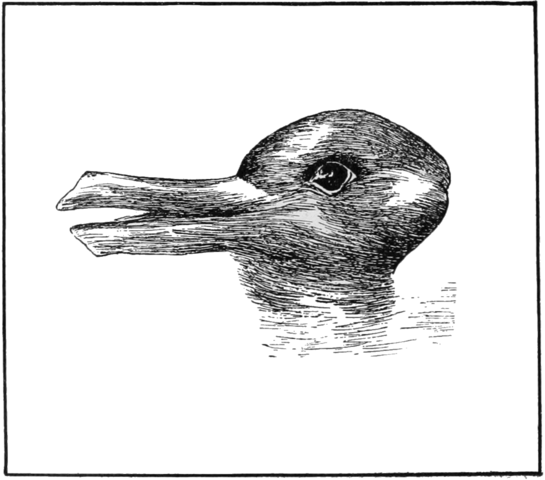
Figure 3: Which animals are most like each other?
The image above can be encoded in ERIS and be referenced with the URN:
urn:erisx:AAAADEQ445USOXW3JWYK255G4CQABSGYHAOQB7WA46APBTRBNWFAXAOPMK6OOYEN73BNFVWR6YNU6YN2SFQPRCUOHXSOPIZKCULJTR5XP5QQ
Which could be referenced from encoding of metadata:
"image": { "comment": "A duck.", "href": "urn:erisx:AAAADEQ445USOXW3JWYK255G4CQABSGYHAOQB7WA46APBTRBNWFAXAOPMK6OOYEN73BNFVWR6YNU6YN2SFQPRCUOHXSOPIZKCULJTR5XP5QQ", "mediaType": "image/png" }
Somebody might however disagree and think this is more appropriate metadata:
"image": { "comment": "A rabbit.", "href": "urn:erisx:AAAADEQ445USOXW3JWYK255G4CQABSGYHAOQB7WA46APBTRBNWFAXAOPMK6OOYEN73BNFVWR6YNU6YN2SFQPRCUOHXSOPIZKCULJTR5XP5QQ", "mediaType": "image/png" }
Both are valid descriptions (metadata) of the image. By not supporting metadata in the content such ambiguities can be handled without duplicating the content itself.
The format in which metadata is encoded is also not prescribed. We suggest using an RDF based description that is well adapted for content-addressing (see Content-addressable RDF).
3.3 Authenticity of content
ERIS can be used to ensure integrity of content. To ensure authenticity we propose using a RDF vocabulary for Ed25519 cryptographic keys and signatures: RDF signify.
3.4 Namespaces
Namespaces are groupings of content that themselves have an identifier. The members of a namespace may be dynamic. Namespaces are a fundamental building block for organizing content and building applications.
There are many legitimate ways of implementing namespaces. ERIS does not provide a built-in mechanism.
In the following we give an overview of some mechanism and illustrate how ERIS can be used.
We believe that a key value of ERIS is the usability from very different namespace mechanisms. A collection of ERIS encoded content can be served from a HTTP server or be added to a Secure Scuttlebutt feed. By referencing the same content with the same identifier from different systems we can make content interoperable.
3.4.1 Centralized server
A dynamic namespace can be implemented with a HTTP server.
A GET request to a certain URL (e.g. /collections/example) returns a list of references to ERIS encoded content. The URL is the identifier of the namespace.
The members of /collections/example can be modified with PUT and DELETE requests (potentially authenticated).
The server maintains the list of members in a database.
This is how very many HTTP services work (including ActivityPub).
3.4.2 Hypercore and Scuttlebutt
hypercore and Scuttlebutt provide a secure distributed append-only log.
References to ERIS encoded content can be added to such logs.
Hypercore and Scuttlebutt can also be used as storage and transport layer for blocks (add the blocks to the append-only logs).
3.4.3 Commutative replicated data types
Commutative replicated data types (CRDTs) are data containers where operations to modify the content naturally reach consistent states [shapiro2011comprehensive].
There are many different CRDTs (e.g. a set or a register) with different characteristics.
Together with the P2PCollab project we intend to do further research in how CRDTs can be used for peer-to-peer collaboration.
Previous work includes Dedalus [alvaro2010dedalus] and Vegvisir [karlsson2018vegvisir].
3.5 Filesystem
It is possible to encode an entire file system in ERIS by first packing the files and directories in an appropriate container and then encoding and storing. This would allow similar functionality to IPFS (which uses UnixFS).
Individual files can be accessed efficiently as ERIS allows random read access to content (see Radon Access).
Possible container formats include tar or SquashFS.
4 Related Work
4.1 An Encoding for Censorship-Resistant Sharing (ECRS)
ECRS [Grothoff_2003] is the encoding used in the file-sharing application of GNUNet. ERIS is very much inspired by ECRS.
Similar to ERIS, ECRS splits up content into uniform sized blocks (32kB) and combines them to a single root reference.
Unlike ERIS, ECRS encrypts using the hash code of the block as a key (instead of a signle read key). Building the Merkle tree is simpler than in ERIS as there is no distinction between data blocks and tree nodes. However in addition to the reference to the block the key needs to be stored in a parent node (content-hash key).
The reason for developing ERIS in contrast to just using ECRS is the verification capability. This allows blocks that are required to reassemble some content to be cached by a peer holding the verification capability, without being able to read the content.
ECRS also provides two namespace mechanisms (SBlock and KBlock). Both mechanisms can be implemented with ERIS as well.
4.2 Datashards
Datashards is a secure storage foundation for the web. Work on ERIS was inspired by Datashards. It provides means for immutable as well as mutable storage.
Datashards (immutable) splits encrypted content into uniformly sized blocks (called chunks) and combines them in a hash list. There is no verification capability for immutable storage.
Mutability is implemented with an append-only log (similar to Hypercore and Scuttlebut).
A key functionality ERIS shares with Datashards is the usability from the web by encoding capabilities as URNs.
Datashards is still in development and in further work we hope to converge ideas and encoding.
4.3 Cryptosphere
Cryptosphere was an experimental research project for securely publishing and distributing content based on Tahoe-LAFS and Freenet (among others).
The key innovation in Cryptosphere is the “repair capability” which allows enumeration of all block required to reassemble content as well as verifying integrity.
To enable the repair capability two (linked) Merkle trees are constructed, one allowing read capability and one allowing repair capability.
The constructions of the tree is slightly more involved than in ERIS.
4.4 Other
Other related projects include Tahoe-LAFS and Freenet. We refer the reader to the ECRS paper [Grothoff_2003] which provides an excellent description and comparison.
5 Conclusion
This is part of my reversing entropy plan - that hopefully will clear up the mess we’re in.
— Joe Armstrong, The web of names, hashes and UUIDs
We present a scheme for encoding content that enables content-addressing, confidentiality and robustness. The key novelty is the verification capability that allows peers to cache the entire content without being able to read the content (as opposed to peers who do not hold any capability and only see uniformly sized blocks with random content).
Furthermore we hope to motivate the usage of content-addressing for applications beyond peer-to-peer filesharing. ERIS is capable of encoding large files as well as small bits of content such as messages or notes on social media. In particular ERIS is useable with existing web technology and RDF (by providing an URN). Further work details how RDF can be made content-addressable with ERIS (Content-Addressable RDF).
We intend to implement the work presented in the context of the openEngiadina project in order to enable offline-first and decentralized applications.
Many thanks to Serge Wroclawski and Christopher Lemmer Webber (who are working on Datashards) for inspiring this work and discussions that shaped many aspects of ERIS. Thanks as well to TG (from P2PCollab) for the many pointers in the right directions.
This work has been supported by the NLNet Foundation trough the NGI0 Discovery Fund.
6 Appendix
6.1 Size of Merkle tree
How big is the Merkle tree in relation to the size of the content to be stored? This relation captures the storage overhead and the computational overhead of the Merkle tree.
The parameters are:
- \(s_h\): size of the hash code
- \(s_b\): block size
- \(s_d\): size of the data to be stored
To simplify the calculations we assume that the block size is always chosen as a multiple of \(s_h\):
\[ s_b = k s_h \]
Nodes in the Merkle tree have size \(s_b\) and can hold at most \(k\) child references. \(k\) is the arity of the Merkle tree (in diagrams we have \(k=2\)).
We also assume that the size of the data to be stored is a multiple of the block size:
\[ s_d = n s_b \]
\(n\) is the number of blocks the data is split into.
For example the data we want to store is split up into 8 blocks (\(n = 8\)) and two child references fit into a block (\(k = 2\)):
Figure 4: Merkle tree with 8 data blocks
We are interested in the number of nodes in the Merkle tree (the yellow boxes) in relation to the number of data blocks (white boxes).
Let us call the number of nodes in the Merkle tree \(m\).
We can start counting the number of nodes in the Merkle tree from the top:
\[ m = 1 + k + k^2 + k^3 ... + \frac{n}{k} \]
At the root level there is one node, at the level below \(k\) and below \(k^2\) - at every level we go down there are \(k\) times more nodes. At the bottom level (level 0) there are \(\frac{n}{k}\) nodes (this is also \(log_k(n) - 1\)).
\(m\) is a geometric serie and can be simplified:
\begin{align*} m &= 1 + k + k^2 + k^3 ... + \frac{n}{k} \\ mk &= k + k^2 + k^3 + ... + \frac{n}{k} + n \\ mk - m &= m(k - 1) = n - 1 \\ m &= \frac{1}{k-1}(n-1) \end{align*}The size of the Merkle tree is linearly proportional to \(n\) with \(\frac{1}{k}\). In big O notation: The size of the Merkle tree is \(O(\frac{n}{k})\).
If we choose a block size that fits exactly 2 child references (\(k=2\)), the Merkle tree will consist of at most half the number of data blocks - the storage overhead is 50%.
Assuming \(s_h = 32 \mathrm{B}\) (\(256 \mathrm{bit}\)) we have following block sizes and storage overheads:
| \(k\) | block size | overhead |
|---|---|---|
| 2 | \(64 \mathrm{B}\) | 50% |
| 32 | \(1 \mathrm{kB}\) | 3.125% |
| 64 | \(2 \mathrm{kB}\) | 1.6% |
| 128 | \(4 \mathrm{kB}\) | 0.8% |
| 256 | \(8 \mathrm{kB}\) | 0.4% |
| 512 | \(16 \mathrm{kB}\) | 0.2% |
| 1024 | \(32 \mathrm{kB}\) | 0.1% |
| 32000 | \(1 \mathrm{MB}\) | 0.003125% |
Bibliography
- [Polleres_Kamdar_Fernández_Tudorache_Musen_2020] Polleres, Kamdar, Fernández, Javier David, Tudorache & Musen, A more decentralized vision for Linked Data, Semantic Web, 11(1), 101–113 (2020). link. doi.
- [liedtke1995micro] Liedtke, On micro-kernel construction, ACM SIGOPS Operating Systems Review, 29(5), 237-250 (1995).
- [aumasson2013blake2] Aumasson, Neves, Wilcox-O’Hearn, Zooko & Winnerlein, BLAKE2: simpler, smaller, fast as MD5, 119-135, in in: International Conference on Applied Cryptography and Network Security, edited by (2013)
- [saarinen2015blake2] Saarinen & Aumasson, The BLAKE2 cryptographic hash and message authentication code (MAC), Internet Engineering Task Force, (2015). link.
- [nir2015chacha20] Nir & Langley, ChaCha20 and Poly1305 for IETF Protocols, Internet Engineering Task Force, (2018). link.
- [Zooko2008] Wilcox-O'Hearn, Drew Perttula and Attacks on Convergent Encryption (2008)
- [shapiro2011comprehensive] Shapiro, Pregui\cca, Baquero, & Zawirski, A comprehensive study of convergent and commutative replicated data types, , (2011).
- [alvaro2010dedalus] Alvaro, Marczak, Conway, , Hellerstein, Maier & Sears, Dedalus: Datalog in time and space, 262-281, in in: International Datalog 2.0 Workshop, edited by (2010)
- [karlsson2018vegvisir] Karlsson, Jiang, Wicker, , Adams, Ma, van Renesse, & Weatherspoon, Vegvisir: A partition-tolerant blockchain for the internet-of-things, 1150-1158, in in: 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), edited by (2018)
- [Grothoff_2003] Grothoff, Grothoff, Horozov, & Lindgren, An encoding for censorship-resistant sharing (2003)

An Encoding for Robust Immutable Storage by openEngiadina is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.